

概述
不同于C/C++,java语言有着自动垃圾回收机制,这让程序员免于手动操作对象或其他资源回收问题,提高了实际开发效率。但是在实际工程中,当需要排查各种内存溢出、内存泄漏问题时,当垃圾收集成为了高并发系统的瓶颈时,垃圾回收机制的原理就是绕不开的一道坎,因此对于这些“自动化”的技术仍然有着必要去深入了解。
对于java虚拟机内存结构,其中对于线程独占区的程序计数器、虚拟机栈、本地方法栈3个区域的内存随着线程而生灭,栈帧随着方法的开始和结束有序入栈与出栈,因此这3个区域的内存回收与分配不需要过多考虑。
而对于线程共享区的Java堆和方法区,它们由多个线程共享,每个线程对于内存的要求都是不同的,只有在程序运行时才能知道具体情况,因此这部分的内存回收与分配是我们需要关注的。
对象是否存活
虚拟机进行垃圾回收的首要步骤就是判断哪些对象需要回收(即哪些对象已经不再存活了),判断的方法在目前主流java虚拟机中主要为: 引用计数法和可达性分析法
引用计数法
在对象中添加一个引用计数器,每当有一个地方引用这个对象时,计数器的值就+1,当引用失效(如引用对象值置为null),计数器的值就-1,当计数器的值为0时,就判断此时的对象是不可能再被使用的了,就可以被回收了。
缺陷:
- 引用计数法存在一个巨大的缺陷:当两个或多个对象互相引用,它们的计数器就不会为0,那这些对象就不可能被垃圾回收了。在IDEA中的run选项,进入找到Edit Configurations,然后找到当前类的配置项,在VM options中添加
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23/**
* @author xcz
* @ClassName Test.java
* @createTime 2020年03月25日 19:03:00
* @Description: 测试引用计数法进行垃圾收集
*/
public class Test {
public Object instance = null;
private static final int num20MB = 1024*1024*20;
private byte[] BigStorage = new byte[num20MB]; //此时此数组所占内存为20MB
public static void main(String[] args){
Test test1 = new Test();
Test test2 = new Test();
test1.instance = test2;
test2.instance = test1;
test1 = null;
test2 = null;
System.gc();
}
}-verbose:gc -XX:+PrintGCDetails就能打印出GC的详细日志
从程序中可以看到,有两个Test对象,每个对象有一个20MB大小的数组,然后执行System.gc(), 输出日志:
从图中我们可以看到,此次System.gc()回收了大约40MB的内存,由此可以判断java8的垃圾回收中并不是使用的引用计数法寻找垃圾对象。
可达性分析法
基本思路:通过一系列的称为“GC Roots”的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链,当一个对象到GC Roots没有任何引用链时,则证明此对象是不可用的,可以进行回收了
示例: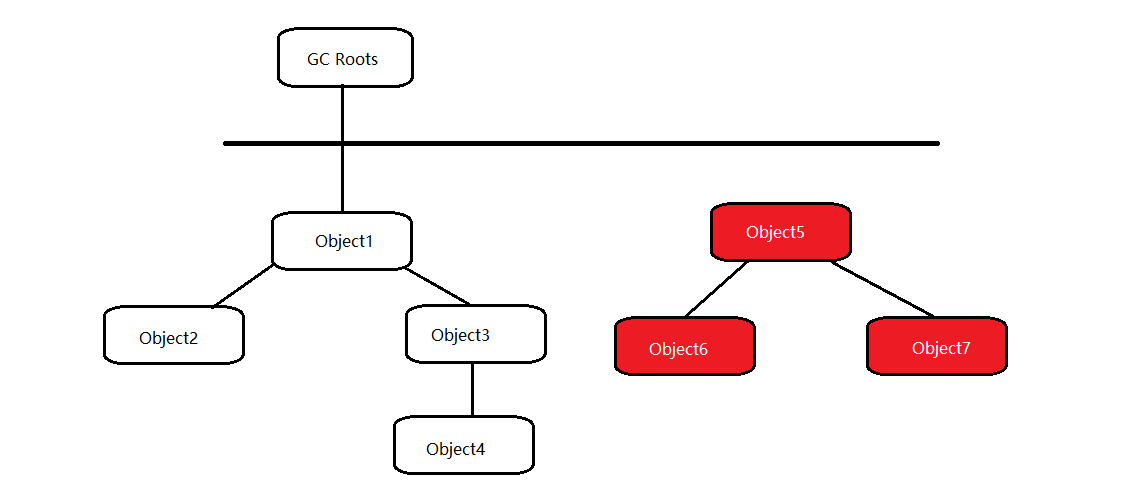
图中的Object5、Object6、Object7三个对象虽然彼此之间存在引用关系,但是由于从GC Roots不可达,仍然属于需要被回收的范畴。
GC Roots是一组必须活跃的引用:
- 所有Java线程当前活跃的栈帧里指向GC堆里的对象的引用;换句话说,当前所有正在被调用的方法的引用类型的参数/局部变量/临时值。 (线程独占区指向线程共享区)
- VM的一些静态数据结构里指向GC堆里的对象的引用
- java本地接口句柄
- (看情况)所有当前被加载的Java类
- (看情况)Java类的引用类型静态变量
- (看情况)Java类的运行时常量池里的引用类型常量(String或Class类型)
- (看情况)String常量池(StringTable)里的引用
注意,是一组必须活跃的引用,不是对象。
GC Roots的选择必须完整全面,不然会漏掉一些应该存活的对象,导致这些对象被误回收了。
分代式GC对GC roots的定义有什么影响呢?
答案是:分代式GC是一种部分收集(partial collection)的做法。在执行部分收集时,从GC堆的非收集部分指向收集部分的引用,也必须作为GC roots的一部分。
具体到分两代的分代式GC来说,如果第0代叫做young gen,第1代叫做old gen,那么如果有minor GC / young GC只收集young gen里的垃圾,则young gen属于“收集部分”,而old gen属于“非收集部分”,那么从old gen指向young gen的引用就必须作为minor GC / young GC的GC roots的一部分。
继续具体到HotSpot VM里的分两代式GC来说,除了old gen到young gen的引用之外,有些带有弱引用语义的结构,例如说记录所有当前被加载的类的SystemDictionary、记录字符串常量引用的StringTable等,在young GC时必须要作为strong GC roots,而在收集整堆的full GC时则不会被看作strong GC roots。
换句话说,young GC比full GC的GC roots还要更大一些。
总结:就是从非收集部分中的引用设置为GC Roots,指向GC收集部分,当收集部分中有对象处于引用链,就不需要回收了,因为这些对象是非收集部分中引用所需要的对象。
一般情况下,Java语言中可以作为GC Roots的对象包括:
- 虚拟机栈(栈帧中的本地变量表)中的引用的对象
- 方法区中的类静态属性引用的对象
- 方法区中的常量引用的对象
- 本地方法栈中JNI的引用的对象
垃圾回收算法
标记清除法
通过判断对象是否存活的算法标记区分对象后,在随后的阶段,通过STW(Stop The World,中断整个JVM中程序的执行)的形式将需要回收的对象清除。
缺点:
- 效率:标记与清除的过程性能较低
- 空间问题:将对象直接清除,会造成越来越多的不连续的内存空间出现,如果后序找不到合适的内存大小分配给新对象,就可能会再次触发垃圾回收,十分消耗性能。
复制清除法
思想:将内存划分为两块,一块区域未使用,一块区域已经使用,在垃圾回收时,将不需要回收的对象全部复制到另一块区域,然后将原本的区域整体回收,这样就能得到一块连续的内存区域,如此循环两块区域即可。
为了方便内存回收,jvm的堆内存进一步细分:
- 新生代
- Eden区:新创建的对象基本都会放到这个区域
- Survivor区:在Eden区的对象,经过了GC后而存活下来,就会移到Survivor区
- Survivor1(from)
- Survivor2(to)
- 两个survivor区,一般只使用其中一个,另一个备用。这样两个survivor就可以使用复制清除算法。
- 当复制清除时,另一个区域如果装不下放过来的对象,就需要内存分配担保机制,将这些放不下的对象,放到老年代里去。
- Ternured区:在Survivor中,经过了多次GC都存活下来了,就会移动到Tenured区
- 老年代
- 在新生代中存活多次GC(默认15次)后,就会移到老年代中
- 大对象直接进入老年代
可以看出,复制清除算法主要针对的是新生代内存。
标记整理算法
复制算法在存活对象较多时进行对象复制就比较消耗资源,效率会降低,并且会浪费一块额外的空间作为备用区域。
因此老年代区域一般不使用复制清除算法。
标记整理算法:标记过程与标记清除的过程相同,但是标记完成后,会将所有存活的对象整体都向一端移动,然后直接清理掉端边界以外的内存。
分代收集算法
即将java堆划分为新生代、老年代,每种代又各自具体进行划分。
然后根据不同区域的具体情况分别使用不同的垃圾回收算法,如
- 新生代使用标记复制算法
- 老年代使用标记整理算法
参考


- 本文作者: xczll
- 本文链接: https://xczllgit.github.io/2020/03/25/jvm/2020-03-25-jvmGarbageCollection/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!